-
[ Open Data Structures ] - Skiplists - 1DataStructure 2021. 7. 28. 17:28
Skiplists
이번엔 다양한 활용이 가능한 Skiplist라는 아름다운 자료구조를 공부해보록 합니다. 이 자료구조를 사용하여 우리는 Add, Get, Set, Remove을 O ( log(n) )의 Running time을 갖는 List interface를 구성할 수 있으며 모든 오퍼레이션이 Expected running time이 O ( log(n) )을 취하는 Sorted Set을 구성할 수도 있습니다.
Skiplist의 효율성은 랜덤화에서 기인합니다. 새로운 자료가 Skiplist에 추가될 때 Skiplist는 무작위 동전 던지기와 같은 기법으로 새로운 자료의 높이[Height]를 결정하곤 합니다( 곧 이 높이에 관해서 논할 겁니다 ). Skiplist의 성능[Performance]은 Expected Running time과 경로길이[Path Length]로 표현됩니다. 그리고 이 Running time은 Skiplist가 수행하는 동전 던지기에 의해 결정됩니다. Skiplist에서 무작위 동전 던지기는 Pseudo-Random Number Generator로 시뮬레이팅 됩니다.
The Basic Structure

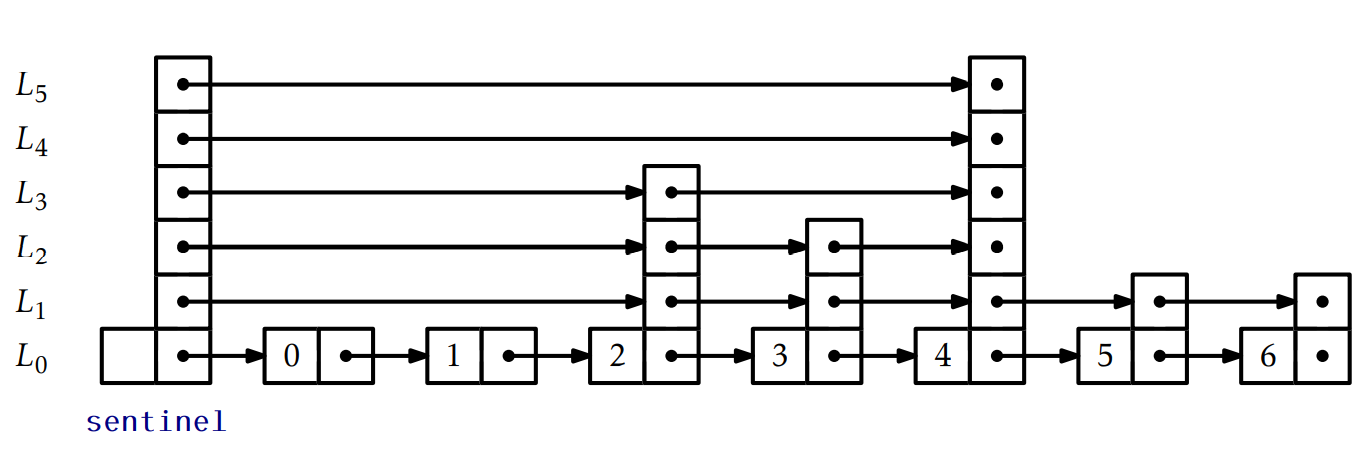

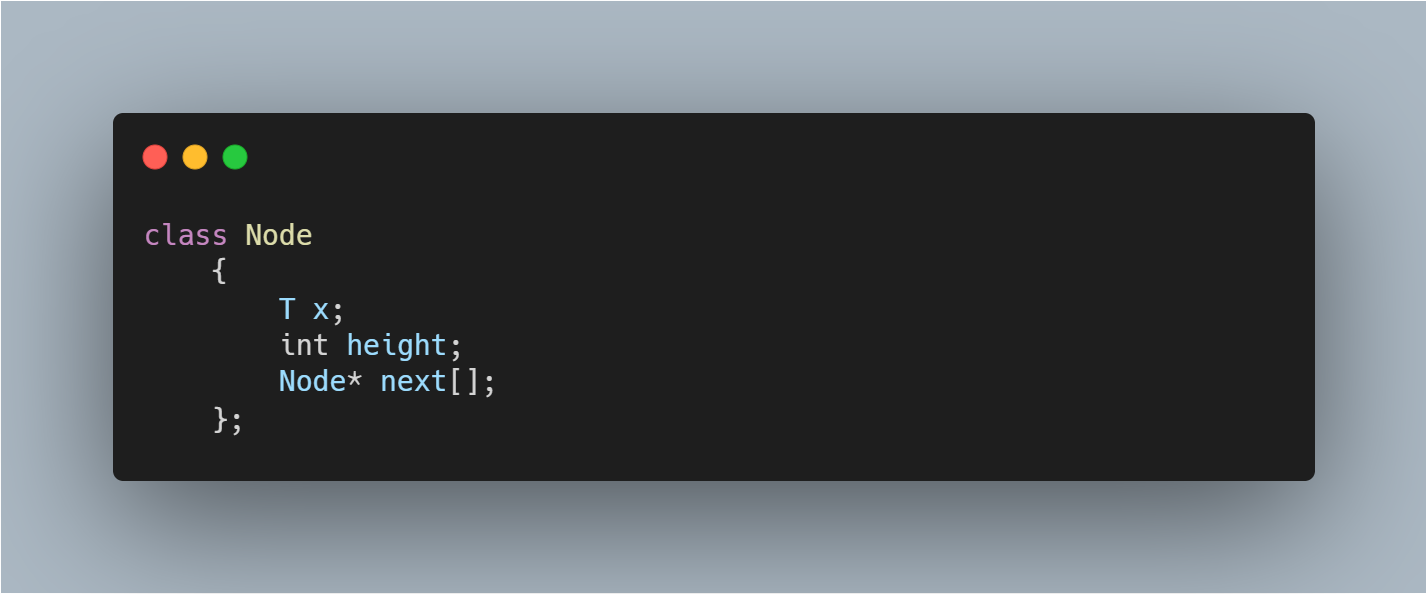

SkiplistSSet : An Efficient SSet




조금 복잡한 것 같습니다. 하지만 별 것 아닙니다. m과 z를 bit연산 하는 겁니다. 무작위 z값을 받고 m을 1부터 왼쪽으로 1bit씩 Shift하며 &연산을 했을 때, 0이 되는 값, 즉 z의 bit를 반전한 값을 높이로 차용하는 방법입니다.
Add Operation
Add operation은 복잡합니다. 추가하려는 정보를 x라고 합시다. 그러면 x가 들어가야 할 L0의 linked list 내의 자리를 찾고 임의의 높이 k를 PickHeight()로 결정한 뒤 그곳에 넣습니다.(원문 : 継ぎ足す 로 추가하여 길게 늘인다는 의미가 있습니다.) 이를 가장 편리하게 구현하는 방법은 Stack을 이용하는 방법이 있습니다. 탐색경로(探索経路 or path)가 있을 때, Lr에서 Lr-1로 내려가는 노드를 Stack에 쌓는 것입니다. 더 정확하게 말하면 Lr에서 Lr-1로 내려갈 때, Lr을 Stack[r]에 저장하는 겁니다. 이렇게 하면 L0에 어떤 노드가 삽입 되었을 때, 수정되어야 할 남은 노드들을 모아 놓을 수 있습니다. 이 실장[実装 or Implementation]이 다음과 같습니다.
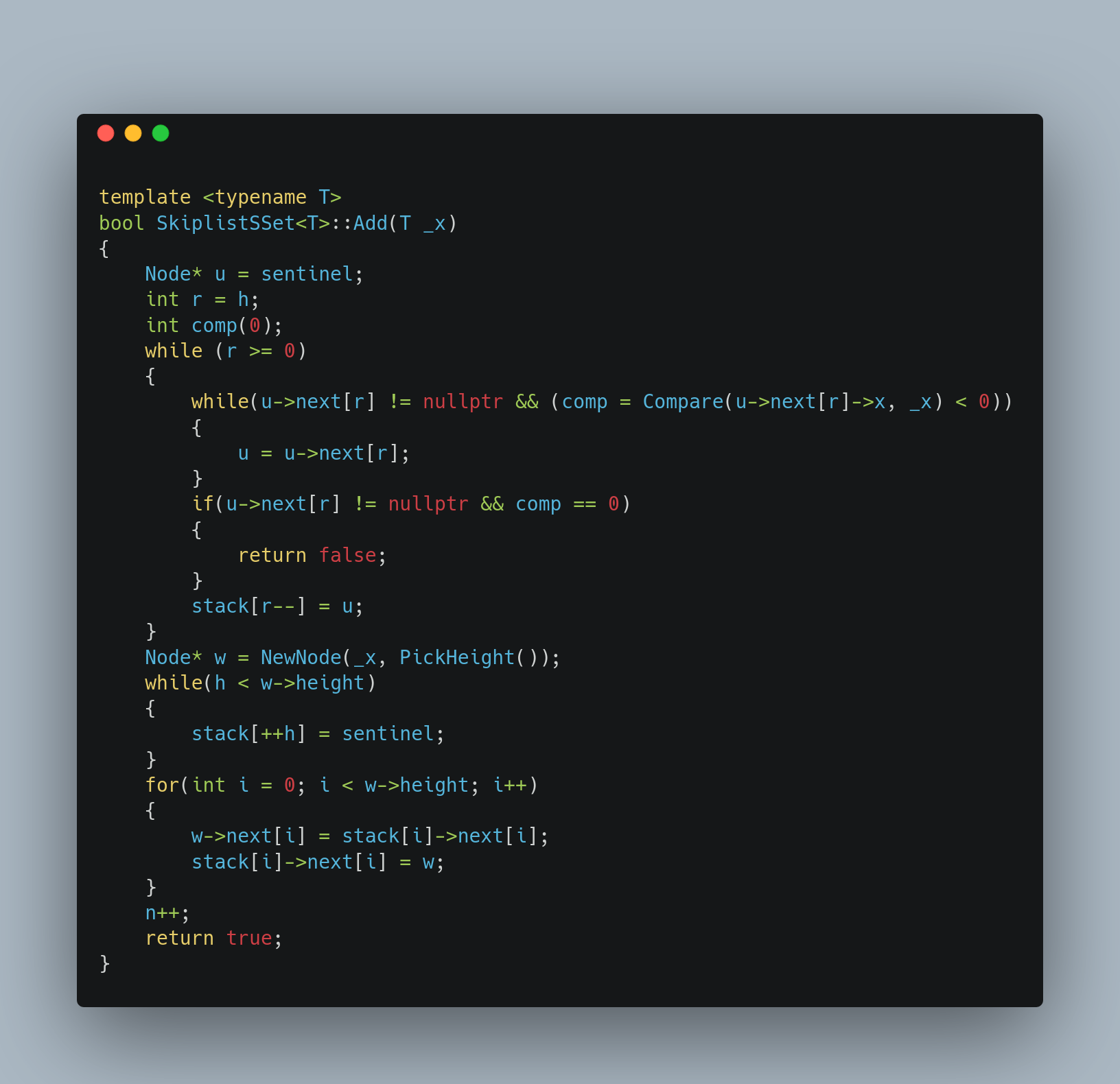
복잡합니다. 하지만 천천히 하면 두려울 것이 없습니다. 추가 될 노드의 높이[高さ or height]는 분명 세 가지의 경우의 수가 존재합니다. 추가 되기 전의 Skiplist의 전체 높이보다 작거나 크거나 혹은 같은 경우입니다. 만약, 추가될 노드의 무작위 높이가 기존의 높이보다 낮거나 같아면 아무 상관이 없습니다. 하지만 더 높아졌다면, 이 Skiplist의 전체 높이를 반드시 올려주어야 합니다. 그 과정 역시 Stack을 통해 이루어 집니다. 그리고 해당 과정은 노드를 만들고 등장하는 While문에서 코드로 구현되어 있습니다.
그러면 마지막 for(int i = 0; i < w->height; i++)의 역할이 궁금합니다. 선언된 모든 변수들의 정의를 이해했다면 어렵지 않습니다. 분명, 노드에 포함된 next[i]는 L_{i} level(층 또는 linked List)에서 해당 노드 다음에 올 노드를 가리킨다고 했습니다. 그리고 Stack에는 어떤 노드를 찾다가 Lr에서 Lr-1로 내려가는 순간에 Lr을 stack[r]에 집어 넣기로 했습니다.
그러면 Stack[0]에는 L0의 어떤 노드가 있을 것입니다. Stack[1]에는 L1, Stack[2]에는 L2, ... , 그리고 바로 직전 While문에서 새롭게 추가된 노드의 높이가 기존의 높이를 초과했을 경우 Stack[++h]에 Sentinel을 추가함으로써 추가한 노드까지 타고 온 노드에 초과된 분량까지 더해 Skiplist의 최대 높이까지 맞춰 주었습니다. 이제 그림을 보면서 이해해야 합니다.
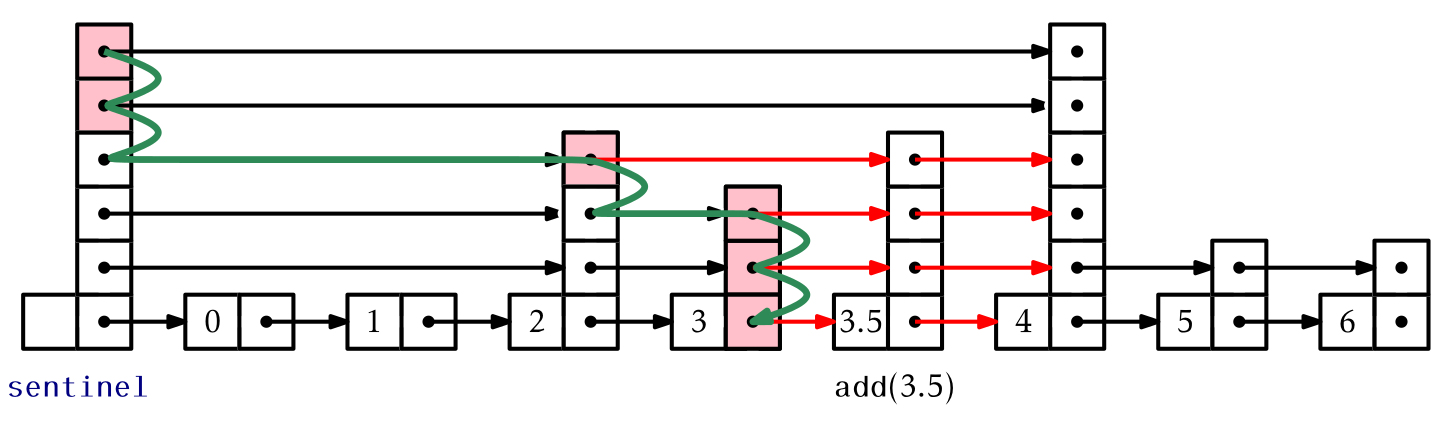
w->next[i] 는 새롭게 추가된 노드 w의 L_i층의 다음 노드, 즉 w보다는 큰 노드를 가리킵니다. 그건 어디에 있겠습니까? Stack[i]->next[i]에 있습니다! 이 Skiplist의 좌상단에서 시작하며 Stack[r]에 Lr을 집어 넣었기 때문에 Stack[0]에는 L0에 해당하는 노드가 있기 때문입니다. 그래서 w->next[i] = Stack[i]->next[i]는 w보다 큰 값 바로 뒤에 노드를 추가하는 과정인 것입니다. 그러면 w가 삽입되기 전에, w보다는 작은 어떤 값의 다음을 w로 연결해주면 됩니다. Stack[i]->next[i] = w;이 바로 그 과정입니다. 이제 Skiplist를 이해함에 있어서 어려운 과정은 모두 넘겼습니다!
그리고 NewNode함수는 다음과 같이 정의되어 있습니다.

Remove Operation
Remove Operation도 같은 원리입니다. 차이가 있다면 remove에서는 탐색 경로를 저장할 Stack이 필요하지 않다는 점입니다. 삭제할 값을 찾아가는 과정에서 처리할 수 있기 때문입니다. 위의 3.5를 추가하는 그림을 보면서 코드와 교차하여 비교하면 이해가 아주 쉽습니다.


이렇게 SkiplistSSet은 Sorted Set Interface를 implementation할 수 있습니다. 모든 Add, Remove, Find는 O(log(n))입니다.
'DataStructure' 카테고리의 다른 글
[ Open Data Structures ] - Skiplists - 3 (0) 2021.07.29 [ Open Data Structures ] - Skiplists - 2 (0) 2021.07.29 [ Open Data Structures ] - Space-Efficient Linked List - 2 (0) 2021.05.14 [ Open Data Structures ] - Space-Efficient Linked List - 1 (0) 2021.05.14 [ Open Data Structures ] - The model of Computation (0) 2021.05.06