-
[ Open Data Structures ] - Space-Efficient Linked List - 1DataStructure 2021. 5. 14. 13:13
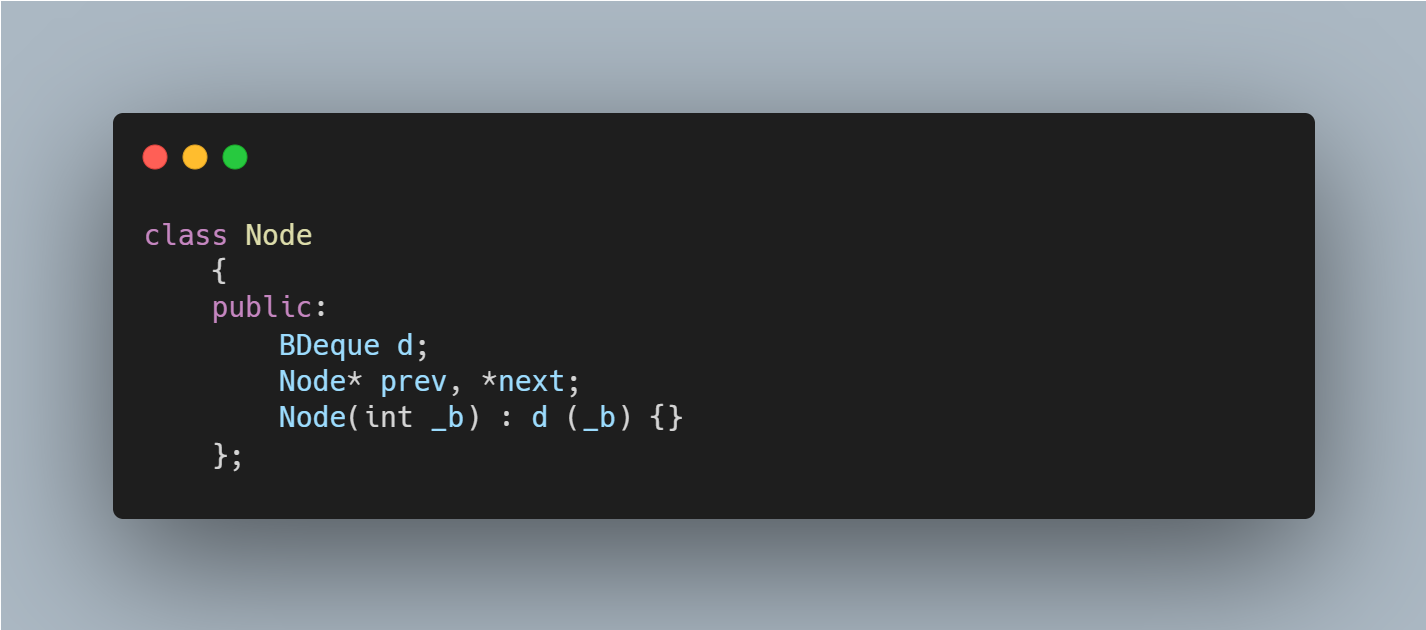
Linked List의 깊은 곳에 위치한 Node에 접근하는 시간적인 비용을 차치하고도 Linked List엔 단점이 하나 존재하는데 그것은 공간의 효율성이다. DLList의 각 Node는 해당 Node의 전후를 가리키는 Prev와 Next 두 개의 Reference 혹은 Pointer를 요구한다. DLList의 Node를 보면 prev, next와 실제 정보를 저장하는 x의 총 세 개의 Field로 이루어져 있는데 이들 중에서 실질적으로 정보를 저장하는 Field는 x밖에는 없다.
따라서, Space-Efficient Linked List(以下SEList)는 DLList에 개별의 자료/원소를 저장하기 보다는 몇 개의 자료를 포함하는 Array/Block을 사용하여 공간의 낭비를 줄인다. 조금 더 상세하게는 SEList는 block의 크기 b라는 수로 매개변수화(Parameterised)된다. SEList의 각 Node는 b+1개의 자료를 포함하는 block을 저장한다. 후에 더 명확해지겠으나 각 Block에서 Deque operation을 수행할 수 있다면 좋다. 각 Block에 대해 Deque operation을 수행할 수 있도록 하기 위해 Array Deque에서 파생된 Bounded Deque(以下BDeque) 가 가진 자료구조를 선택한다.
Space-Efficient Linked List
BDeque는 Array Deque와 작은 차이점이 하나 존재하는데 BDeque는 생성될 때 Backing Array의 크기가 언제나 b+1의 크기로 고정되어 줄거나 팽창하지 않는다 ( Resize()를 호출하지 않는다) . BDeque의 가장 중요한 성질 중 하나는 Add나 Remove의 작업을 Front, Back 어디에서 접근하든 상수시간 내에 해결할 수 있다는 점이다. 이는 하나의 Block에서 다른 Block으로 원소가 이동할 때 상당히 유용하다.

동시에 SEList는 블록으로 이루어진 Doubly Linked List ( DLList )이기도 하다.
Space Requirments
SEList는 각 Block에 존재하는 자료의 숫자에 대해 상당히 엄격한 기준을 적용한다. 마지막 Block이 아닌 이상, 그 블록은 최소 b-1개, 최대 b+1개의 자료를 저장하고 있어야 한다. 이는 곧 SEList가 n개의 자료를 저장하고 있다면 SEList는 최대 n / (b - 1 ) + 1개 = O( n / b )의 블록을 갖고 있다는 뜻이다.
BDeque에서 각 블록은 b+1크기의 배열을 갖고 있지만 마지막 블록을 제외한 모든 블록이 이 배열에서 Constant Space을 낭비한다. 블록에 의해 사용되는 다른 메모리 역시도 Constant다.
By choosing a value of b within a constant factor of √ n, we can make the space-overhead of an SEList approach the √ n lower bound.
Finding Elements
첫 번째로 마주할 문제는 어떤 index i가 주어졌을 때, SEList 내에서 List Item을 찾는 일이다. 이때, 자료의 위치는 두 가지의 요소로 이루어져 있음을 상기한다.
1. index i와 자료를 포함하는 블록을 포함하는 노드 u
2. 블록 내의 자료의 index j

특정한 자료를 갖고 있는 블록을 찾기 위해서 우리는 DLList의 방법을 그대로 따른다. 원하는 자료를 찾을 때까지 List ( 아마, 노드들의 연결을 대충 이르는 말 )의 처음에서 Forward로 Traverse 하거나 List의 마지막에서 backward로 Traverse한다. 여기서 DLList와 유일한 차이는 한 노드에서 다른 노드로 넘어간다는 것은 모든 블록 내의 자료를 넘어간다는 점이다.

최대 하나의 블록을 제외하면 각 블록은 최소 b - 1개의 자료를 갖고 있기 때문에 한 번의 단계 ( 한 번의 탐색 )가 거듭될 때마다 찾고자 하는 원소까지 b - 1개의 자료만큼 가까워진다. 만약 우리가 정방향으로 탐색하고 있다면 O (1 + i / b ) 단계 이후에 해당 자료에 도달할 수 있다는 뜻이다. 역방향으로 탐색 중에 있다면 O ( 1 + ( n - i ) / b ) 단계 이후에 찾는 자료에 도달할 수 있다. 이 알고리즘의 성능은 찾고자 하는 자료의 위치에 의존하기 때문에 정방향이든 역방향이든 빠른 쪽이 될 것이다. 따라서 이 함수는 O (1 + min{ i, n - i} / b )의 Running time을 갖는다.
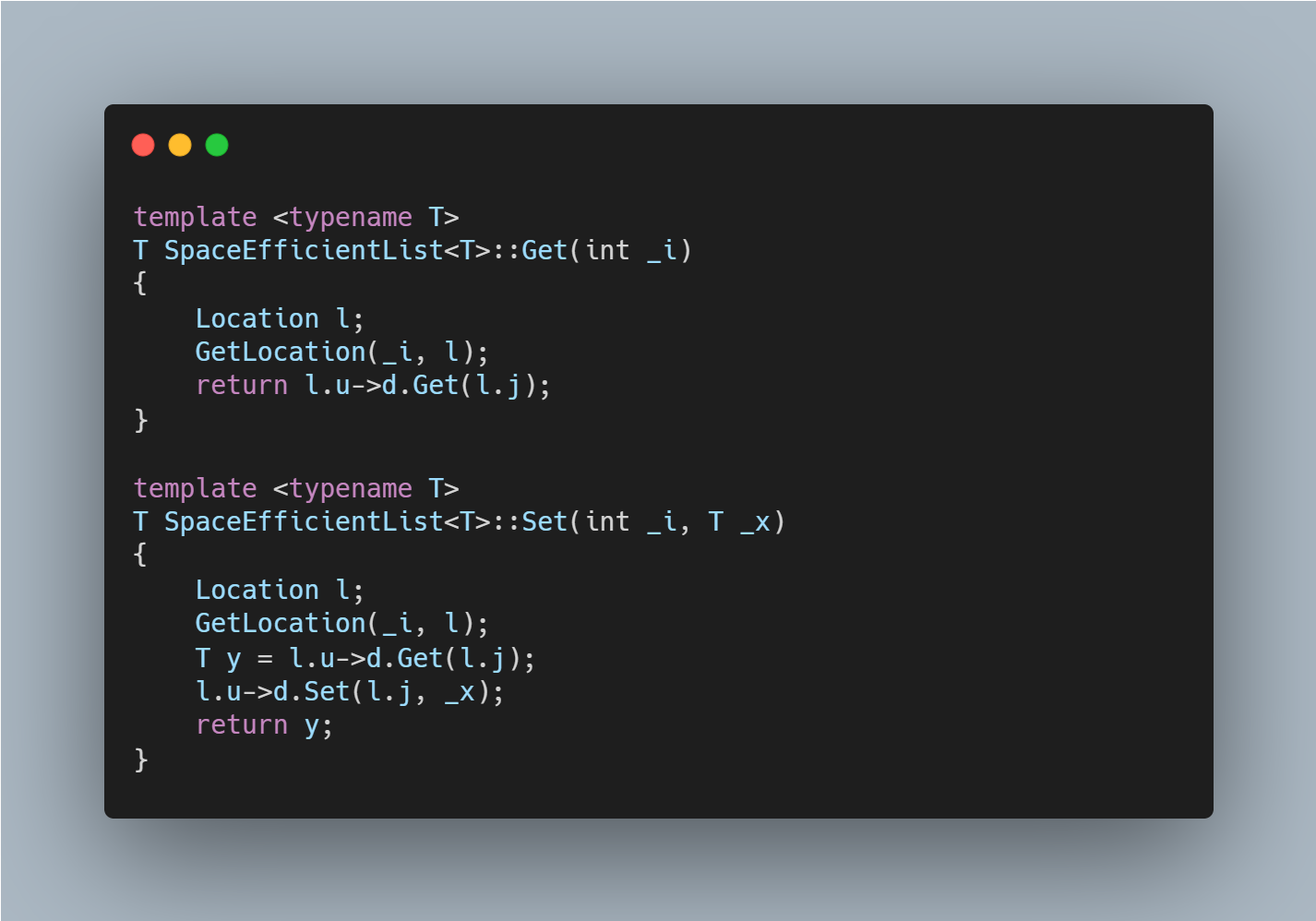
이 두 함수의 Running time은 Location Instance의 위치를 찾는데 지배되고 DLList의 탐색을 사용하기 때문에 O ( 1 + min{i , n - i} / b )이다.
Adding an element
자료를 SEList에 추가하는 건 더 복잡하다. 일반적인 경우를 고려하기 전에 자료 x가 리스트의 끝에 추가되는 상황을 생각해본다. 만약, 마지막 블록이 가득 차 있거나 블록 자체가 존재하지 않는 상태라면, 먼저 블록을 위한 메모리를 할당하고 이를 리스트의 끝에 붙인다. 그렇게 하면 마지막 블록이 분명 존재하고 가득 차 있지 않는 상태라는 점을 확신할 수 있고 자료 x를 추가할 수 있다.

Add(int _i, T _x)를 사용한 함수를 구현하기 시작하면 이건 더 복잡하고 어려워져서 미치는 줄 알았다. 가장 먼저 i번째 자료를 저장하고 있는 블록을 갖고 있는 노드 u의 위치를 찾는다. 여기서 해결해야 할 문제는 바로 자료 x를 노드 u의 블록에 저장하고 싶은데 이미 해당 블록이 b + 1개의 자료를 갖고 있어서 x를 위한 공간이 없는 경우다.
u0, u1, u2, ... ,를 u, u.next, u.next.next, ....를 나타낸다고 가정하자. 이들을 순차적으로 탐색하면서 추가할 자료 x를 위한 공간이 있는지 없는지 검토한다 . 몇 가지의 경우를 나누어서 생각해 볼 것인데 이 경우들은 아래의 그림 속에 나타나있다.
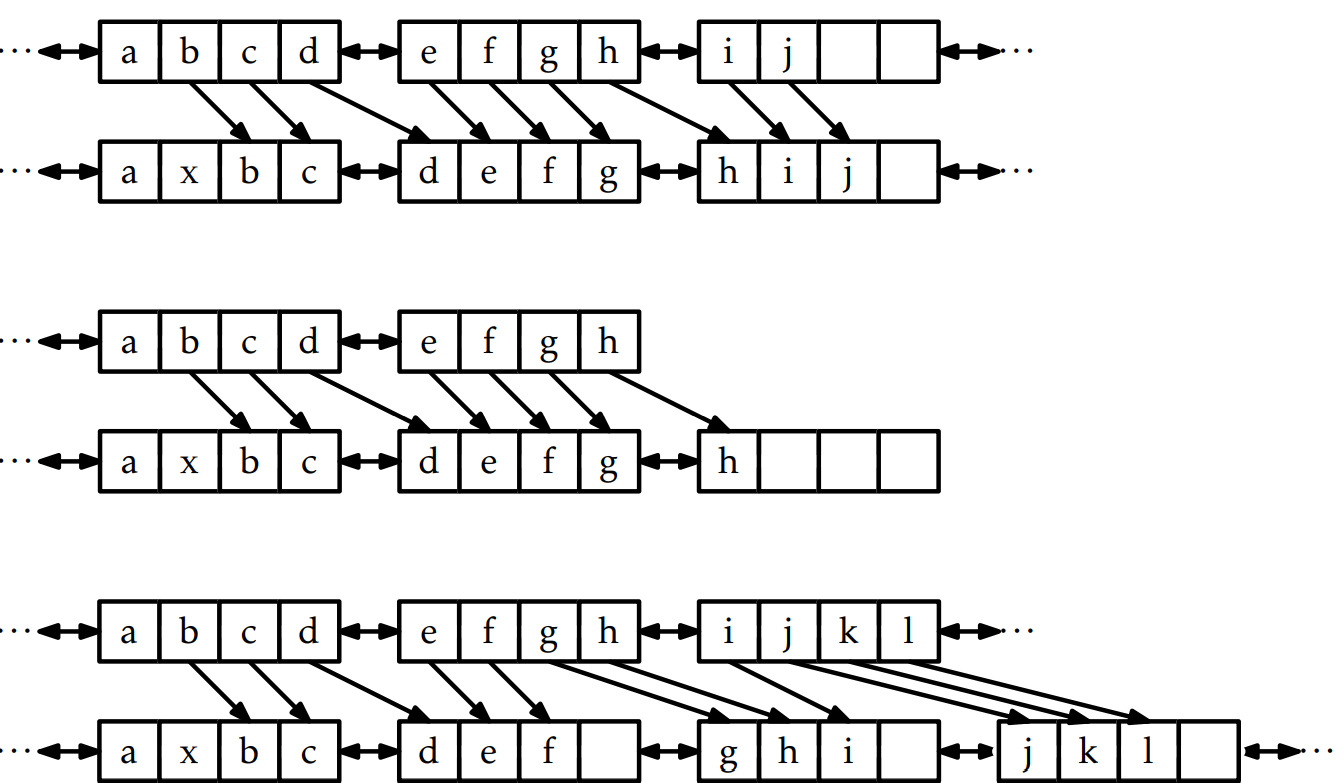
자료 x를 추가하는 모습 


'DataStructure' 카테고리의 다른 글
[ Open Data Structures ] - Skiplists - 1 (0) 2021.07.28 [ Open Data Structures ] - Space-Efficient Linked List - 2 (0) 2021.05.14 [ Open Data Structures ] - The model of Computation (0) 2021.05.06 [ Open Data Structures ] - Randomisation and Probability (0) 2021.05.06 [ Open Data Structures ] - Asymptotic Notation (0) 2021.05.05