-
[정리] - The graph theory and the DFS, BFS methods - 1정리 2021. 10. 1. 22:16
DFS, BFS은 응용하기 참 까다롭습니다. 왜 Queue을 사용하는지, 왜 Stack인지, 왜 재귀인지 받아들이는 것이 어렵습니다. Graph Theory에서 배우는 간단한 용어를 알고 있으면 좋습니다. 어떤 식으로 BFS와 DFS의 논리가 작동하는지 뼈대를 알아야 응용함에 있어서 어려움을 최소화 할 수 있다고 믿습니다.
The number of edges
일반적으로 간단한 그래프[Simple Graph]는 임의의 정점[Vertex, Node]의 집합과 엣지[Edge]들의 집합으로 구성되어 있습니다. 그리고 그래프는 다시 크게 Directed Graph와 Undirected Graph로 나눌 수 있습니다. 이름이 직관적으로 설명하는 것처럼 전자는 정점과 정점 사이에 방향이 존재하지만 후자는 그렇지 않습니다. 그렇다면 n개의 정점을 갖는 어떤 간단한 Directed Graph가 있다고 했을 때, 이 그래프의 가능한 최대의 Edges의 개수는 n Permutation 2로 구할 수 있습니다. Undirected Graph는 방향이 존재하지 않기 때문에 엣지 1-2와 엣지 2-1같습니다. 따라서 n choose 2 혹은 n Combination 2로 구할 수 있습니다.
Walk and Path
어떤 그래프를 순회하면서 거치는 Edges들의 집합입니다. 만약 각 정점들을 딱 한 번씩만 거쳐서 Walk을 형성했다면 이건 Path라고도 부를 수 있습니다. 또 정점u 와 정점v사이에 walk나 path가 존재한다면 우리는 u is reachable from v라고 할 수 있으며 Undirected Graph라면 반대로도 말할 수 있습니다.
만약 walk의 시작 정점과 종결 정점이 일치한다면 이 walk를 Closed Walk라고 부릅니다. 이 Closed Walk을 순회함에 있어서 어떤 그래프 G의 정점들로 구성된 부분집합(혹은 부분 그래프) G'의 정점들이 딱 한 번씩 등장했다면 이 Closed Walk는 Cycle입니다.
만약 Undirected graph가 어떠한 Closed Walk 또는 Cycle을 갖고 있지 않다면 우리는 이 'Undirected Graph'를 Acyclic이라고 부를 수 있습니다. 중요한 것은 이 Acyclic을 Forest라고도 부른다는 것입니다. 마지막으로 Spanning Tree라는 것이 있는데 이는 어떤 Connected undirected graph의 정점들을 모두 포함하는 path을 일컫는 말입니다.
Data structures
이해하기 조금 벅찼던 부분입니다. 왜? 그리고 어떻게 그래프를 코드로 구현할 수 있는 것이지? 대체 어떻게 돌아가는 것이지? 통상적으로 Adjacency lists, Adjacency Matrices로 표현합니다. 한편으로는 둘 다 정점들로 채워진 배열이나 어떤 Container을 의미하는 것이긴 합니다. 이 리스트와 행렬을 채운 것은 일반적으로 어떤 정수(대신 1부터 정점의 개수 V사이입니다.)이며 이 수가 각 정점들을 나타냅니다.
Adjacency Lists
가장 보편적으로 쓰이는 그래프의 표현법이라고 하지만 알고리즘 문제를 풀면서 느낀 바로는 그런 것 같지가 않습니다. 이 리스트를 쓰려면 입력 값으로 어떤 임의의 정점 u에 대해서 인접한 정점 또는 노드들을 순차적으로 받아야 하는데 많은 문제들이 이런 친절함을 베풀지 않았습니다. Undirected Graph의 경우에 다음과 같이 Singly linked list를 사용해서 저장할 수도 있습니다. 문제에서 그래프를 어떻게 주는지, 무엇을 해결해야 하는지 잘 파악한 후에 자료의 구조를 결정하는 것이 가장 합리적입니다. Singly Linked List의 경우엔 출발, 도착 위치를 명확히 알 때 가장 빠른 경로를 탐색할 때 쓰면 좋겠다는 생각이 듭니다.

figure 1a
Adjacency Matrices
문제를 풀 때 가장 편리한 방법인 것 같습니다.
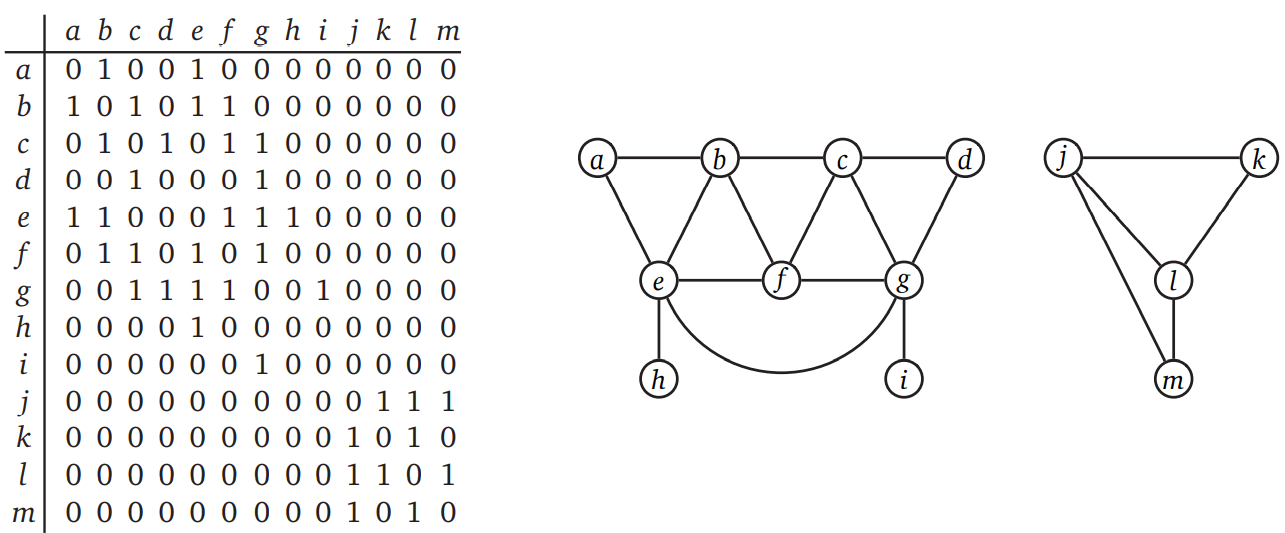
figure 1b 이런 식으로 행렬을 만들어서 연결된 정점 사이에 표시를 하는 방법입니다. 물론 Cost가 모두 1인 경우이기는 하지만 대부분의 문제를 간편하게 풀 수 있다는 장점이 있었습니다. 또 많은 문제들이 이런 식으로 그래프의 입력을 줬습니다.
Depth-First Seach
기본적인 흐름은 이렇습니다.

또는

먼저 재귀적인 방법을 해석해봅니다. Parameter로 받은 것은 Vertex,Node 즉 정점입니다. 어떤 정점을 받으면 해당 정점을 탐색했는지 안 했는지 파악하고 탐색을 안 했다면 탐색을 했다는 것으로 표기를 해주고 정점 v와 연결된 모든 정점 w에 대해서 다시 재귀적으로 w을 호출합니다. 이게 어떻게 깊이를 우선적으로 탐색하게 되는 것인지 어떻게 작동하는지 생각해 봐야 합니다. 그래야 DFS을 활용해야 풀 수 있는 문제를 어렵지 않게 풀 수 있습니다.
많은 문제를 풀어본 것은 아니지만 몇 가지 정형화 된 입력 값이 있는 것 같습니다. 하나는 연결된 엣지를 주는 경우, 다른 하나는 (x,y) 형식으로 주어지는 경우, 그리고 0과 1로 표기된 행렬 전체를 주는 경우. 물론 이 밖에도 아주 다양한 것들이 있습니다. DFS, BFS을 연습하기 위해서 임의의 그래프를 생성하는 간단한 장치를 하나 만들었습니다.

figure 2a type_1은 첫 번째 경우입니다. 즉, u->v로 연결되어 있다는 사실을 나타냅니다. 이건 Undirected 일수도 Directed일수도 있습니다. 두 번째 타입인 type_2는 행렬의 형태로 주어집니다. 즉, M x N 행렬이면 각 (x,y)에 True or False 형태로 주어지며 x->y 또는 y->x가 이어져 있는지 그렇지 않은지 표현합니다. 당연히 문제는 친절하지 않기 때문에 순환하는 구조의 그래프일 가능성까지 포함합니다. 참고한 문제는 백준의 알고리즘 문제 1260번 입니다.

figure 2b 입력의 첫 째 줄은 무시하고 두 번째 줄부터 간선[Edge]의 수를 줍니다. 다음과 같은 코드로 이 입력의 형태를 재현할 수 있을 것입니다.

figure 2c 테스트를 해보면 다음과 같은 결과를 얻을 수 있습니다. 실행할 때마다 다르고 테스트 케이스의 크기는 나름대로 조정을 하면 됩니다. 제 경우에는 너무 많은 건 보기도 힘들고 싫으니까 10개의 정점[Vertex 또는 Node]으로 제한했습니다.

figure 2d-1 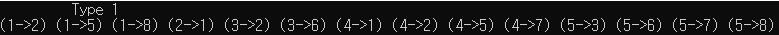
figure 2d-2 
figure 2d-3 백준 문제와 다른 점이라면 제가 만든 케이스는 양방향이 아니라는 점입니다. 그렇게 구성할 수도 있습니다. 그러나 항상 친절한 문제만 마주하는 것이 아니기 때문에 단방향이며 순환하는 길[Path]이 존재한다는 생각을 염두에 두고 하겠습니다. 그렇다면 이렇게 생성한 테스트 케이스에 대해서 DFS로 순환하는 코드를 짜면서 DFS을 이해해보도록 합니다.
Recursive Depth-First Search
제가 가장 선호하는 방법은 문제에서 주어진 가장 큰 값을 기준으로 어떤 Container을 미리 만들어 두는 것입니다. 제가 스스로 가정하기를 정점의 개수는 아무리 많아도 10개를 넘지 않는다고 했으니 다음과 같은 두 개의 컨테이너를 만듭니다.

figure 3a vertices는 잘 보면 이차원 벡터이며 초기화가 벡터를 격납할 벡터는 최대 크기인 11개, 그 안은 크기가 0입니다. 아래의 visit은 말 그대로 어떤 정점이나 노드를 방문했는냐 그렇지 않느냐 확일할 컨테이너 입니다. 백준 1260은 입력이 한 정점과 다른 정점 사이의 간선이기 때문에 vertices[검사할 정점의 번호][이 정점과 연결된 정점들]으로 해석할 수 있습니다. 해당 인덱스의 값이 0이 아니면 두 정점 사이엔 간선이 있는 것으로 간주합니다.
예를 들어서 1번과 3번의 노드, 1번과 4번노드, 2번과 5번의 노드가 연결되어 있다면 vertices[1][0] == 3, vertices[1][1] == 4, vertices[2][0] == 5입니다. 즉, vertices[x][y]에서 x는 노드 또는 정점의 번호이고 y는 0번째부터 정점 x와 연결된 정점인 것입니다.
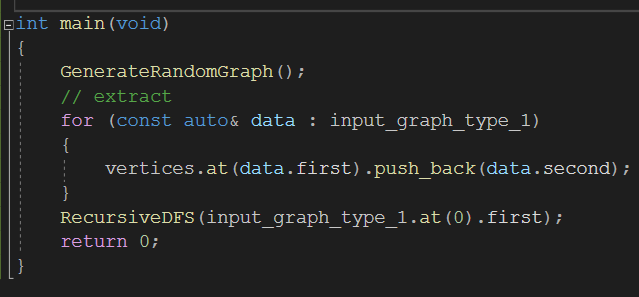
figure 3b GenerateRandomGraph()을 통해서 문제를 만들고 input_graph_type_1에 저장된 간선 정보를 추출하여 vertices에 차곡차곡 쌓는 모습입니다. 이렇게 되면 vertices[정점 u][정점 v]의 형태로 격납이 되며 만약에 vertices[u][v]을 호출한다면 "u와 연결된 간선들을 주세요."라고 요청하는 것과 같습니다.
다시 다음 pseudocode을 살펴봅니다.

figure 3c 처음 보고 이걸 코드로 옮기는 것도 조금 힘들었습니다. 다른 사람이 작성한 Pseudo code을 옮겨 코드로 작성한다는 것 자체가 상당히 낯선 경험이었기 때문입니다. 코드를 천천히 읽어보면 pseudo code와 다른 것이 딱히 없습니다. 처음 parameter로 받은 vertex가 방문을 했는지 안했는지 확인을 합니다. 늘 염두에 두어야 하는 건 코드가 Zero-based 인지 아닌지 입니다. 저는 zero-based을 즐겨 썼는데 나중에 머리가 아파서 그냥 1을 시작으로 두기로 했습니다. 직관적이고 좋긴 합니다.
해당 vertex가 방문을 한 적이 없다면 이제 방문 했으니 visit[vertex] = true을 수행하여 해당 정점은 방문을 했다는 사실을 명시합니다. 중요한 것은 알고리즘 문제를 풀 때 어디서 그리고 어떤 프로세스를 진행할 것인가?라고 생각합니다. 즉, DFS라는 큰 틀 안에서 해결하고자 하는 문제를 적당히 끼워 넣을 수 있어야 한다는 것입니다. 현재 방문 중인 Vertex에 대해서 무언가 수행을 해야한다면, 위의 코드처럼 인쇄를 하는 부분에서 처리를 하면 될 것입니다. 몇 번의 실행을 해보면 적당한 결과를 얻을 수 있습니다.

figure 3d-1 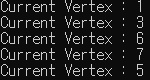
figure 3d-2 위의 코드의 경우에는 모든 정점을 순회하지는 못할 것입니다. 제가 만든 코드는 제일 처음 받은 정점을 시작으로 순회를 합니다. 따라서 무작위로 생성된 그래프는 Spanning tree가 아닐 수도 있기 때문에 단절된 Subgraph을 순회할 수는 없습니다. 물론 이를 해결할 수 있는 방법도 있습니다. 그래프의 모든 정점들을 하나씩 시작 지점으로 두고 순회를 하면 빠짐 없이 순회할 수 있을 것입니다. 대신 이 경우엔 visit을 초기화 하지 않도록 주의를 해야 할 것입니다.
Iterative Depth-First Search
다시 다음 pseudocode을 살펴봅니다.
저는 왜 Stack을 써야 하는지부터 제대로 파악하기 힘들었습니다. 찬찬히 생각해보면 Recursive와 완전히 같은 이유로 Stack을 사용합니다. 다음과 같은 무작위 그래프를 정점 1부터 순회한다고 가정해봅시다.

figure 4a-1 
figure 4a-2 Iterative을 하기 전에 염두에 두어야 하는 것은 While문이 들어가기 전까지는 Setup 과정과 같다는 점입니다. 즉, 우리가 Stack에 정점 1을 쌓기는 하지만 아직은 방문한 적이 없는 일종의 Initial state와 같습니다. 그래서 먼저 정점 1을 스택에 쌓고 While문에 진입을 하면 마침내 순회를 할 준비를 마치게 된 것입니다.
while문에 진입을 하면 조건을 검사합니다. 물론 상황에 따라 다르겠지만 이 경우엔 반드시 적어도 하나의 정점은 Stack에 있기 때문에 진행이 될 것입니다. pseudocode에 따라서 정점 1만 들어 있는 스택에서 pop을 하면 정점 1이 다시 튀어나올 것입니다. 이렇게 튀어나온 정점 1은 방문을 했다는 표식을 남기고 이 정점 1과 연결된 모든 정점들을 스택에 쌓습니다. figure 4a의 예제에 따르면 1과 연결된 정점들은 2,3입니다. 그러면 다시 while문의 조건을 검사하게 될 순간에 Stack에는 { 2, 3 }이 있을 것입니다.
{ 2, 3 }이 있는 스택에서 Pop을 호출하면 나중에 쌓은 3이 먼저 튀어나옵니다. 3에 mark하고 3과 연결된 정점들을 스택에 쌓습니다. 그렇다면 스택은 { 2, 2 }가 될 것입니다. 같은 2가 들어가는 것이 맞습니다. 다시 while문을 검증하고 stack에서 pop을 하면 방금 추가 했던 정점 2가 다시 튀어나옵니다. 그런데 우리는 2를 이미 방문을 했습니다. 따라서 if문에서 false값을 받고 정점 2와 연결된 정점들을 스택에 쌓는 과정은 하지 않게 됩니다. 이제 스택엔 다시 { 2 }만 남았습니다.
만약 정점 3이 다른 정점과 연결이 되어 있었다면 { 2, x, y, z, r, .. , }식으로 스택에 쌓였을 것입니다. 잘 보면 가장 먼저 추가된 정점 2에 대해서는 가장 나중에 검증을 하게 된다는 사실을 알 수 있습니다. 정점 u을 검증한다는 가정이라면 먼저 스택에 u와 연결된 정점들을 모두 쌓고, 가장 나중에 쌓은 정점에 연결된 정점들을 또 쌓고, 정점 u에 Reachable한 마지막 정점부터 검사를 한다는 논리 자체가 한 정점u로 시작해서 최후의 정점v에 이르는 지점까지 무작정 찾아간 다음 Backtracking을 하고 있다는 것과 같은 뜻이었습니다. 후에 공부한 BFS가 왜 Stack이 아닌 Queue을 이용하여 구현하는지 이해할 수 있는 기틀을 닦을 수 있는 이해였습니다. 이 논리의 틀은 Brute Force와 매우 닮아 있어서 개인적으로 어리둥절 했습니다. 어찌보면 둘은 형제나 다름 없는 논리의 틀을 공유하고 있는 건 아닌지 생각을 하게 됩니다.
이제 pseudocode을 코드로 옮겨보면서 복습합니다.
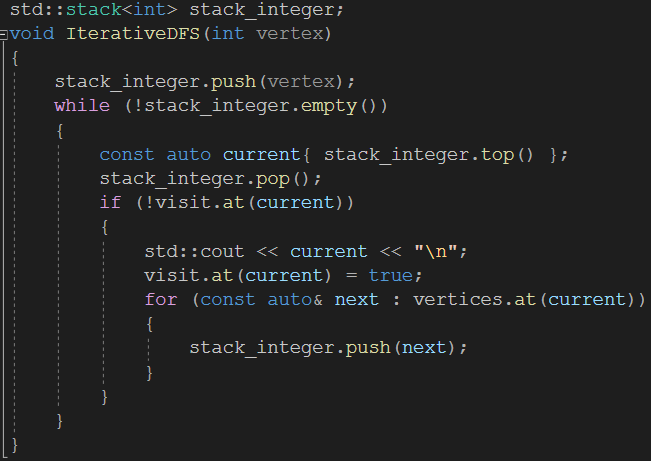
figure 4b vertices와 visit는 RecursiveDFS에서 사용한 것과 정확히 일치합니다. 이 구조는 후에 볼 BFS와 유사합니다. Pseudocode에서 처음 push하는 것이 바로 스택에 초기 노드 또는 정점을 쌓는 것이며 stack_integer.push(vertex)로 구현되어 있습니다. while문을 돌기 시작하면 비로소 그래프를 순회하기 시작합니다.
while에 돌입하고 첫 번째로 마주하는 논리는 스택에서 가장 나중에 들어온 정점을 꺼내 해당 정점에서부터 탐색할 수 있는 정점이 존재하는지 검증하는 것입니다. Definition에 대해서 한 가지 기록할 것이 있는데 Directed Graph에서 가령 정점 u-> 정점 v의 Edge가 존재하면 출발하는 정점u을 tail이라고 하고 v는 head라고 합니다. 또한 u는 v의 Predecessor이며 v는 u의 Successor입니다. 또, u에 연결된 정점의 수를 Degrees라고 하며 u에 연결된 정점들을 Out-Degree, v의 Predecessor의 개수를 In-degree라는 표현을 사용합니다.
아무튼 스택의 최상단에 위치한 정점의 Successor을 탐색하고, Successors의 Successors가 있으면 또 스택에 차곡차곡 쌓습니다. 이런 식으로 하면 한 정점 u에서 Reachable한 모든 정점을 우선적으로 탐색하게 되고 이는 우리가 바라던 일명 깊이 우선 탐색에 부합하는 논리가 됩니다.
'정리' 카테고리의 다른 글
[정리] - The graph theory and the DFS, BFS methods - 2 (0) 2021.10.02 [정리] 퍼즐 조각 채우기 (0) 2021.09.10 9184번 (0) 2021.07.15 1003번 (0) 2021.07.15 14889번 (0) 2021.04.14